PointNet系列处理点云的方法:PointNet、PointNet++、Frustum-PointNet和FlowNet3D
1. PointNet系列
- 参考:https://zhuanlan.zhihu.com/p/44809266
- 点云三大性质:
- 无序性。点云集合顺序不敏感,意味着处理点云数据的模型需要对数据的不同排列保持不变性。目前文献中使用的方法包括将无序的数据重排序、用数据的所有排列进行数据增强然后使用RNN模型、用对称函数来保证排列不变性。由于第三种方式的简洁性且容易在模型中实现,论文作者选择使用第三种方式,既使用maxpooling这个对称函数来提取点云数据的特征。
- 点与点之间的空间关系。一个物体通常由特定空间内的一定数量的点云构成,也就是说这些点云之间存在空间关系。为了能有效利用这种空间关系,论文作者提出了将局部特征和全局特征进行串联的方式来聚合信息。
- 不变性。点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移。论文作者提出了在进行特征提取之前,先对点云数据进行对齐的方式来保证不变性。对齐操作是通过训练一个小型的网络来得到转换矩阵,并将之和输入点云数据相乘来实现(T-Net)。
2. PointNet
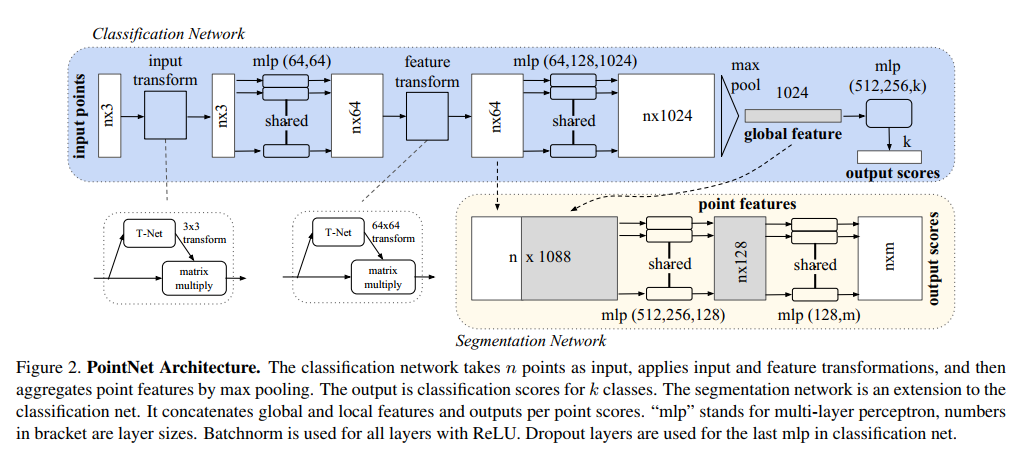
- PointNet的模型结构如上图所示,其关键流程介绍如下:
- 输入为一帧的全部点云数据的集合,表示为一个nx3的2d tensor,其中n代表点云数量,3对应xyz坐标。
- 输入数据先通过和一个T-Net学习到的转换矩阵相乘来对齐,保证了模型的对特定空间转换的不变性。
- 通过多次mlp对各点云数据进行特征提取后,再用一个T-Net对特征进行对齐。
- 在特征的各个维度上执行maxpooling操作来得到最终的全局特征。
- 对分类任务,将全局特征通过mlp来预测最后的分类分数;对分割任务,将全局特征和之前学习到的各点云的局部特征进行串联,再通过mlp得到每个数据点的分类结果。
- 网络重要组成介绍
- T-Net:针对平移或者旋转情况,设计的自适应网络。可学习的一个旋转矩阵,输出$k_1 * k_2$的矩阵,$k_1$是输入层数,$k_2$是输出层数。
- MLP:多层感知机。图中有share的地方用的是1x1卷积表示,每层共享权重。没有share部分直接用的全连接层。
- 分为分类网络和分割网络。分类网络对整个点云分类,分割网络对每一个点分类。顺序和输入点云顺序一致。
3. PointNet++
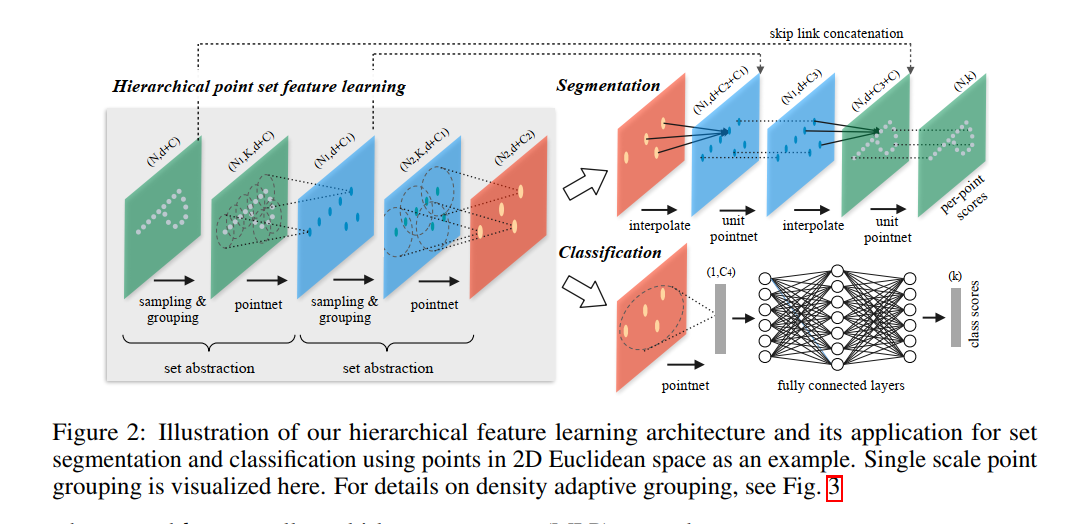
网络构成
PointNet提取特征的方式是对所有点云数据提取了一个全局的特征,显然,这和目前流行的CNN逐层提取局部特征的方式不一样。受到CNN的启发,作者提出了PointNet++,它能够在不同尺度提取局部特征,通过多层网络结构得到深层特征。PointNet++由以下几个关键部分构成:- 采样层(sampling)
激光雷达单帧的数据点可以多达100k个,如果对每一个点都提取局部特征,计算量是非常巨大的。因此,作者提出了先对数据点进行采样。作者使用的采样算法是最远点采样(farthest point sampling, FPS),相对于随机采样,这种采样算法能够更好地覆盖整个采样空间。 - 组合层(grouping)
为了提取一个点的局部特征,首先需要定义这个点的“局部”是什么。一个图片像素点的局部是其周围一定曼哈顿距离下的像素点,通常由卷积层的卷积核大小确定。同理,点云数据中的一个点的局部由其周围给定半径划出的球形空间内的其他点构成。组合层的作用就是找出通过采样层后的每一个点的所有构成其局部的点,以方便后续对每个局部提取特征。 - 特征提取层(feature learning)
因为PointNet给出了一个基于点云数据的特征提取网络,因此可以用PointNet对组合层给出的各个局部进行特征提取来得到局部特征。值得注意的是,虽然组合层给出的各个局部可能由不同数量的点构成,但是通过PointNet后都能得到维度一致的特征(由上述K值决定)。
- 采样层(sampling)
上述各层构成了PointNet++的基础处理模块。如果将多个这样的处理模块级联组合起来,PointNet++就能像CNN一样从浅层特征得到深层语义特征。对于分割任务的网络,还需要将下采样后的特征进行上采样,使得原始点云中的每个点都有对应的特征。这个上采样的过程通过最近的k个临近点进行插值计算得到。
4. Frustum-PointNet
- 上述的PointNet和PointNet++主要用于点云数据的分类和分割问题,Frustum-PointNet(F-PointNet)将PointNet的应用拓展到了3D目标检测上。目前单纯基于Lidar数据的3D目标检测算法通常对小目标检测效果不佳,为了处理这个问题,F-PointNet提出了结合基于图像的2D检测算法来定位目标,再用其对应的点云数据视锥进行bbox回归的方法来实现3D目标检测。F-PointNet的网络结构如下图所示。
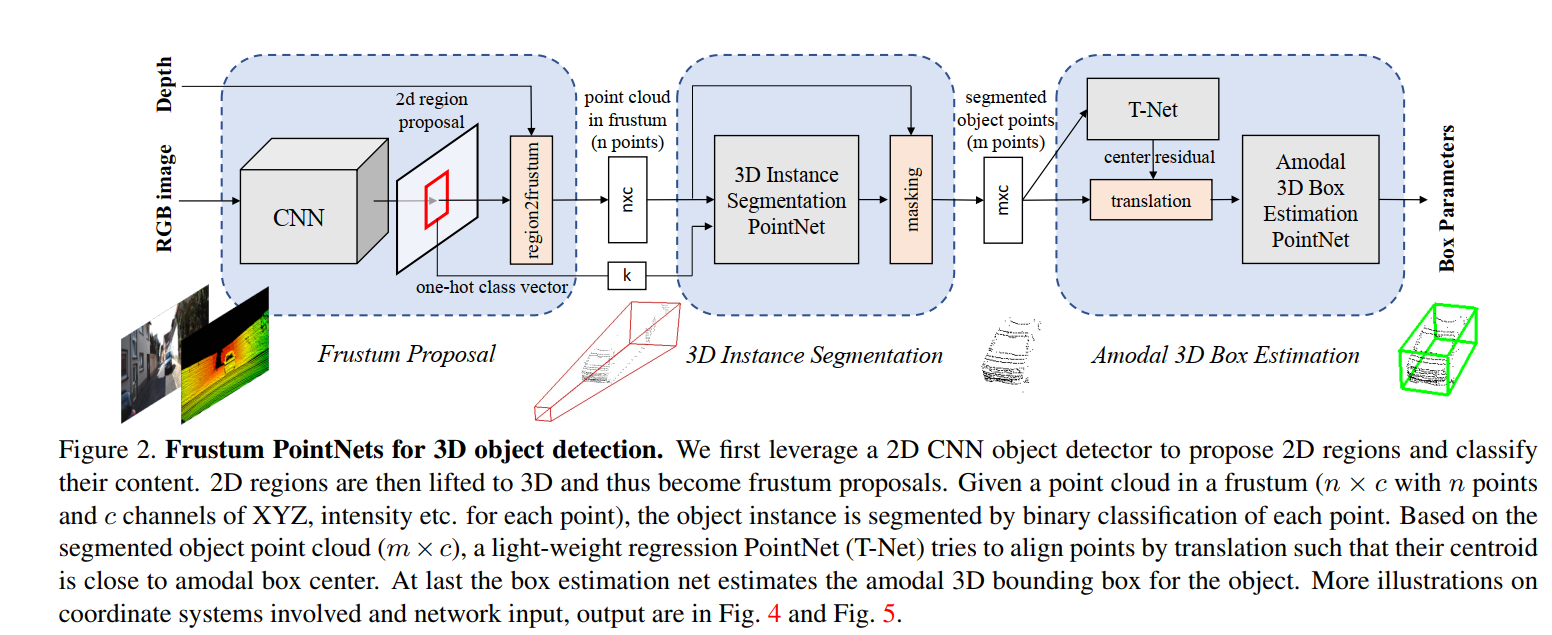
可以看到,F-PointNet主要由以下几部分构成: - 视锥生成(frustum proposal):
首先通过2D目标检测器来定位图片中的目标以及判断它们的类别。对每一个检测到的目标,通过标定好的传感器的内参和它们之间的转换矩阵得到其对应的点云数据中的各点,即点云视锥。作者使用的2D目标检测模型是基于VGG网络的FPN作为特征提取器,并用Fast R-CNN来预测最终的2D bbox。 - 3D实例分割(3D instance segmentation):
对每个得到的点云视锥,通过旋转得到以中心视角为坐标轴的点云数据。对转换后的点云数据用PointNet(或PointNet++)进行实例分割。实例分割是一个二分类问题,用于判断每个点属于某个目标或者不属于。 - 3D边界框回归(3D box estimation):
将上一步实例分割的结果作为mask得到属于某个实例的所有点云,计算其质心作为新的坐标系原点。通过一个T-Net进行回归得到目标质心和当前坐标原点的残差。将点云平移到计算得到的目标质心后,通过PointNet(或PointNet++)对3D bbox的中心、尺寸和朝向进行回归得到最终的输出。此步骤采用的回归方式和Faster R-CNN中类似,不直接回归,而是回归到不同尺寸和朝向的锚点(anchors)。
综上所述,F-PointNet是一个多步骤的3D目标检测算法。如下图所示,为了应对点云数据中各个目标的视角不变性和得到更准确的bbox回归(通过缩小需要回归的值的取值范围),算法需要进行三次坐标转换。模型的loss和2D的目标检测一样是包含分类以及回归的多任务loss。同时,作者提出了一种被称为corner loss的损失函数来对目标的中心、朝向和大小进行联合优化,避免由于某一方面的不准确而主导loss。
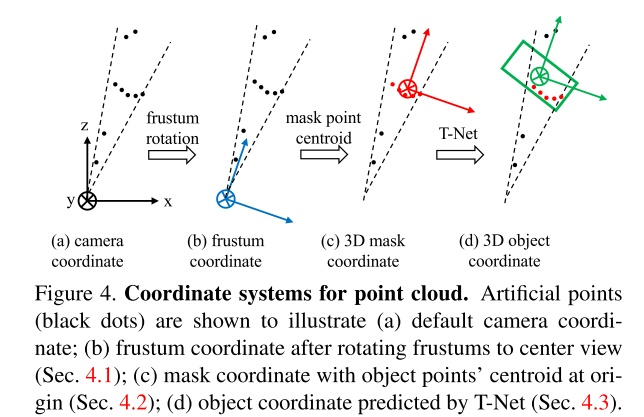
详细参考: https://blog.csdn.net/u011507206/article/details/89106892
5. FlowNet3D: Learning Scene Flow in 3D Point Clouds
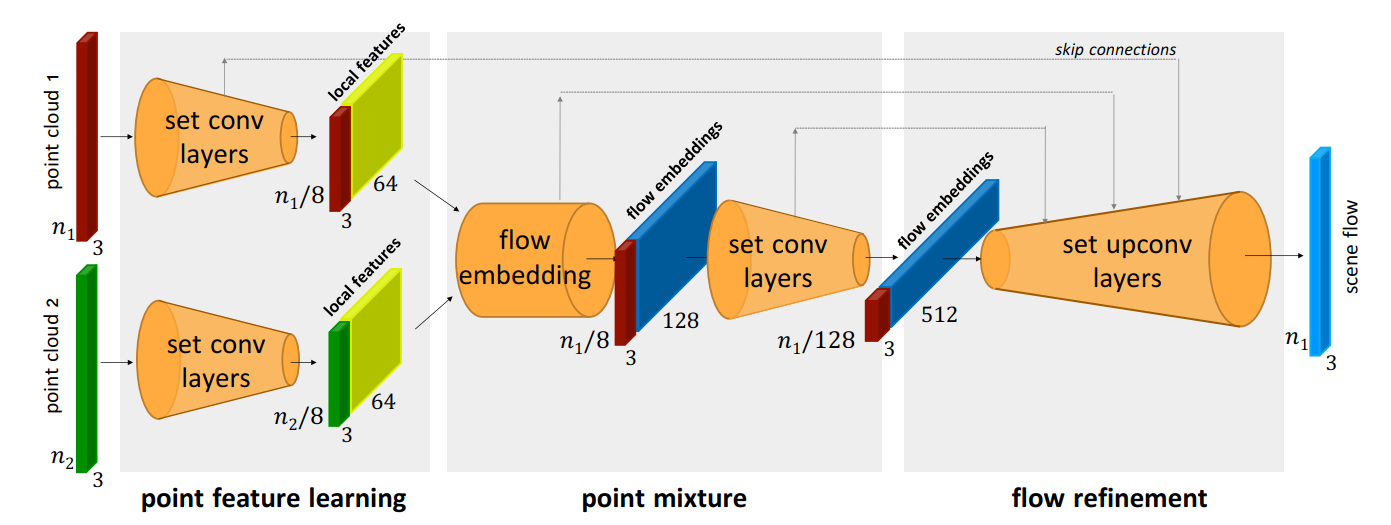
- 通过点云预测光流,整个流程如图所示:后融合之后再进行特征聚合输出最后的结果。set_conv用的pointnet++的结构。flow embedding层来进行前后两帧的差异性提取:
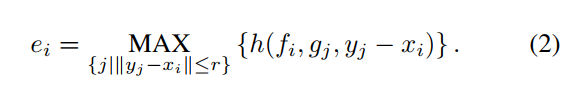
set_upconv用上采样和前面下采样的特折进行skip操作。

